Coding Is Dead, Long Live Programming
Summary
In this post, we argue that the role of a coder now belongs to a coding agent, but that the distinct role of a programmer defines the software engineer's role in interacting with the agent to produce computer programs. At the heart of this, I think, are answers to questions we have about software maintenance, cognitive debt, and the education of junior engineers.
Coding is Dead
Commentators in the tech industry have recently declared that “coding is dead.” The triggers for this statement are:
- LLMs, whose transformer architecture excels at pattern recognition and translation, have achieved a high success rate on key coding tasks, particularly since the December 2025 model releases.
- The improvements in coding agents have pushed the success rate for the code that an LLM generates above the 80% threshold, where agents can begin the journey toward independently doing work without human review for short tasks and increasingly lengthening.
- A broader understanding of good practices in context engineering—using the file system as memory and aggressively managing context by creating fresh agents—has helped prevent the drop in quality caused by context rot.
- The improvement of techniques to capitalize on agents' relentlessness to get them to iterate toward high-quality outputs via clear acceptance criteria for “done-done,” avoiding low-quality output caused by reward hacking. See How To Ralph.
Of course, all statements like “coding is dead” are hyperbolic, but it would be foolish to refute that in 2026 and beyond: agents will write the majority of code.
If coding is dead or will be dead by the early 2030s, what will software engineers do?
Programming is not Coding
The terms programming and coding can seem interchangeable, but historically, they are not the same. They refer to different activities, but for many years we have performed them together, making the distinction unclear.
Following Yourdon and Constantine in Structured Design, we assert that software engineering has the following roles:
- Analyst: talks to the customer to elicit the requirements for what we want to automate.
- Designer: determines how to meet the requirements and required quality attributes of the software, for example, how we split into modules, how those interoperate, scale, provide transactional integrity, etc.
- Programmer: decides on the design of programs: algorithms, data structures, and design patterns – writes coding specifications. QA of the program.
- Coder: implements the program design and has knowledge of syntax.
In the latter two roles, the original distinction between programmer and coder stems from an era when code was often punched out on cards rather than encoded in a high-level language. A programmer handed the coder a coding specification that defined the program to be written:
“Each component subprogram is coded using the coding specifications. Ideally, this phase would be a simple mechanical translation; actually, detailed coding uncovers inconsistencies that require revisions in the coding specifications (and occasionally in the operational specifications).” Bennington, Herbert; Production of Large Computer Programs.
Once, in larger organizations, different people performed the roles of programmer and coder. The programmer specified the required code and handed the resulting coding specification to the coder, who then authored the code to be loaded into the computer.
With the introduction of high-level languages, it became easier for developers to perform both the programming and coding roles simultaneously. The compiler did much of the work that the coder had done before, so the program specification could be completed in parallel with coding. Later, the RAD/agile movements leveraged the ease with which programs could be specified as code was written, speeding up software development by collapsing many steps into a single process and shifting quality left via Test-Driven Development.
It is because of high-level languages and RAD/agile practices that many people use “programming” and “coding” interchangeably. But they are not the same.
Coding or Programming: What is the Difference?
You can reason about this difference easily. Once you learn multiple programming languages, you come to appreciate that all of them have variations of the same concepts: control structures, variables, etc., that only differ by their syntax. By contrast, data structures and algorithms don't depend on specific language syntax. Object-Oriented models of your domain can be developed using CRC cards or UML, without writing code. We think of these concepts as existing outside the syntax and the code, at the level of the program. You can reason about a program in a conversation, or on a whiteboard, without needing to use a specific syntax.
When writing code, you probably used to look up what you needed in documentation or examples and translate it to your domain. These statements were code and reusable as such, once fitted to the logic of your program.
We often overestimate the importance of coding in this merger of roles. It is likely that you spend more of your time as a programmer debating which frameworks and libraries you want to use, and what classes and interfaces form part of your model, than you do over whether you should use a for or while loop.
Knowing which syntax to use in a particular language is the coder's role; knowing what the code should do is the programmer's role.
Alex Booker provides a clear description of the difference between coding and programming in his video Coding or Programming: What Is the Difference?”
XP: Elaboration, CRC Cards, Programming & Coding
Armed with this understanding, it may be helpful to identify when a developer is in a programmer or coder role. Consider the roles we took in an XP-like software development life cycle (SDLC). In a classic XP cycle, the four roles rotate through a familiar sequence. Notice how little time is actually spent in the coder role once you decompose it:

The crucial observation is at the bottom. In pair programming, only one person is ever in the coder role at a time. The other — and, in mob programming, everyone else — is in the programmer role : watching, correlating with the design, and catching any drift.
This is why so many developers underestimate how much of their day is programming rather than coding. You switch roles constantly, and the coder role is always just one half of a pair at most.
Because we have moved away from thinking about the separation of coder and programmer, we have lost sight of how much this classic XP cycle actually shifts focus away from the coder role toward the others.
The Middle Loop
In their book Vibe Coding, Steven Yegge and Gene Kim discuss the Middle Loop, the construction of the context the agent uses when carrying out tasks. We often call this specification-driven development. This agent-assisted loop maps onto the activities of the classic XP loop almost exactly — with two changes: the agent takes the coder role, and a new researcher role emerges that was previously invisible because it was folded into programming.
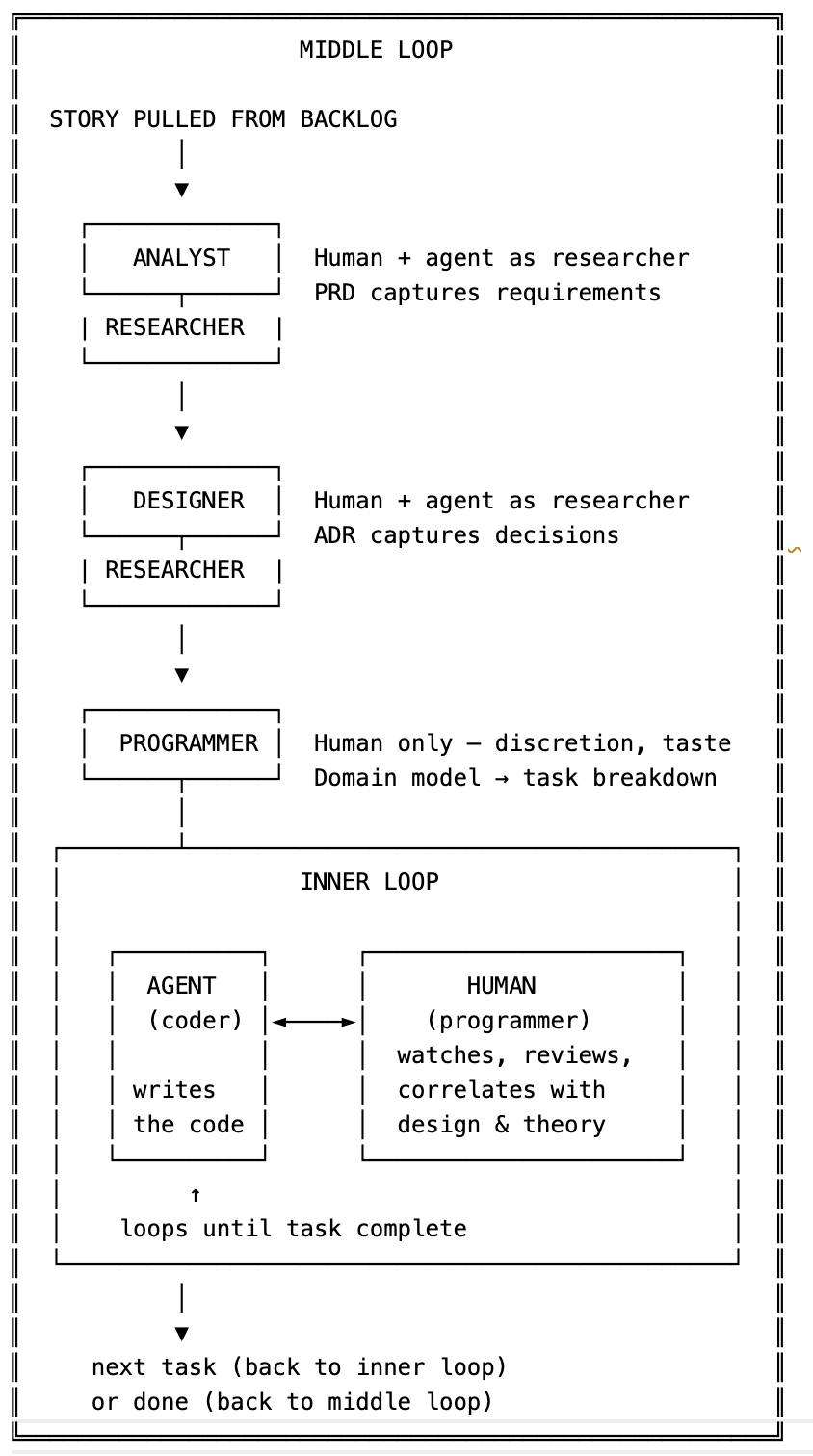
The middle loop runs once per story; the inner loop runs once per task. The loop is fundamentally the same as XP, but the developer no longer performs the coder role.
We introduce a new role of researcher. Previously, when a programmer visited Stack Overflow, read documentation, or extracted candidate objects from a requirements document, it was just another part of the programming process. The agent makes it separable: you can hand “go read the existing codebase and tell me what patterns are established here” to the agent as a discrete task. The agent can help with heavy lifting, but the decision about what to do with that research, based on discernment and taste, remains with the programmer. For that reason, we call this new role: researcher.
What hasn't changed is more important than what has. The analyst, designer, and programmer roles still belong to the human. The inner loop looks like pair programming, where the agent holds the keyboard; the coder role is permanent, but the programmer role, the one that watches and correlates and builds the theory, is still human-in-the-loop.
A speed difference exists, but it is easy to misread. The agent eliminates the friction between “we've agreed on the design” and “the code exists.” It used to be difficult to feed design insights from the inner loop back in — you'd have a better idea, but resist it because of the rework cost. The specification was hard to change. We fell for the “sunk cost fallacy,” but with an agent, you can iterate on the design freely because execution is cheap. The constraint shifts entirely to the quality of your theory.
The key, though, is that much is familiar from our first loop. Even with an agent's help, many roles still fall to the human-in-the-loop.
High-Level Direction Judgement and Taste
“It’s not perfect, it needs high-level direction, judgement, taste, oversight, iteration and hints and ideas. It works a lot better in some scenarios than others (e.g. especially for tasks that are well-specified and where you can verify/test functionality). The key is to build intuition to decompose the task just right to hand off the parts that work and help out around the edges.” Andrej Karpathy, x.com
Judgement, taste, etc., are the programmer's responsibilities. The agent is good at coding, but it needs help deciding what to write. That is why we still need the programmer role and don't simply delegate that to the agent. Maybe one day it will do that role too, but that day is not today.
Watch the Loop
Why suggest that the programmer/coder split is like pair/mob programming, where one partner watches the other? Because the agent needs to be observed.
“It's important to watch the loop as that is where your personal development and learning will come from. When you see a failure domain, put on your engineering hat and resolve the problem so it never happens again.
In practice this means doing the loop manually via prompting or via automation with a pause that involves having to press CTRL+C to progress onto the next task. This is still ralphing as ralph is about getting the most out how the underlying models work through context engineering and that pattern is GENERIC and can be used for ALL TASKS.” Geoffrey Huntley, Everything is a Ralph Loop
Now, we might argue that this is inefficient. Do you need to review the agent's output? It's just coding. Just use a linter and check that it passes the tests.
If agents can produce syntactically correct code indefinitely, what's the actual constraint?
Programming as Theory Building
Peter Naur's essay, “Programming as Theory Building,” states that the most important part of programming is theory building: “ On the Theory Building View of programming, the theory built by the programmers has primacy over such other products as program texts, user documentation, and additional documentation such as specifications.” The theory, the knowledge built up by the programmer in crafting the program, is important for three reasons:
The programmer can explain how the program maps to the problem domain: “the programmer must be able to explain, for each part of the program text and for each of its overall structural characteristics, what aspect or activity of the world is matched by it.”
The programmer can explain the decisions that led to the choices expressed in the program text and documentation.
The programmer understands how to modify the program to support change: “Designing how a modification is best incorporated into an established program depends on the perception of the similarity of the new demand with the operational facilities already built into the program.”
It is the latter point that is key. In large codebases, our ability to maintain a program depends on our understanding of the program's theory. The theory lets you modify the program successfully because you understand how the program's theory should be adjusted to meet the new requirement.
“The point is that the kind of similarity that has to be recognized is accessible to the human beings who possess the theory of the program, although entirely outside the reach of what can be determined by rules, since even the criteria on which to judge it cannot be formulated.”
The risk is that modifications made to a program, without understanding the theory, lead to decay. Most of us have experienced decay when modifications accumulate as additions that don't fit the program's overall theory. Eventually, the program becomes incoherent, and we are forced to rewrite.
“The death of a program happens when the programming team possessing its theory is dissolved. A dead program may continue to be used for execution in a computer and to produce useful results. The actual state of death becomes visible when demands for modifications of the program cannot be intelligently answered. Revival of a program is the rebuilding of its theory by a new programming team.”
Theory is the key to maintenance. If you don't have the theory, you will struggle to maintain the software because you will struggle with the role of a programmer.
“A very important consequence of the Theory Building View is that program revival, that is, reestablishing the theory of a program merely from the documentation, is strictly impossible.”
Code Reviews and Theory Building
In teams that don't use pair programming, a common compensation is to do code reviews. The purpose of both pair programming and code review extends beyond quality assurance; it is about sharing the program's theory.
Often, teams struggle with reviews as flashpoints or have arguments in pairing because they fail to do enough theory-building when they pull the story from the backlog, a process we call elaboration or alignment. A simple way for many teams to improve code reviews is to avoid doing design there but to shift it left into elaboration when the story is pulled from the backlog. This shifts the theory building to an earlier step. The review then just confirms that the code matches the theory. Conflict arises when the theory is unclear during pairing or review.
Pair programming and code reviews spread the theory through the team. Junior developers often don't have the same facility with theory-building as senior developers. Pairing, or code reviews, allow developers to exchange the theory through conversation and reach alignment.
These exchanges work best when they focus not on the code but on the program's theory.
The danger is that a new developer on the team, who has yet to build the program's theory, in conversation with other developers, incorrectly specifies the program without it. Without the theory, their programming specification is likely to be wrong, and the resulting code will be wrong.
InnerSource, OpenSource, and Theory Building
OpenSource, or InnerSource, projects often encounter this need to help contributors acquire theory. Often, Open-source projects identify tasks that require less theory to help new contributors get started. Once contributors establish a track record, maintainers begin investing time in helping them understand the theory.
LLMs and Theory Building
The LLM cannot be used in the analyst, designer, or programmer roles, only as a researcher to support, because it cannot capture the theory of the program as expressed by Naur.
- The LLM does not have the context that lives outside the code, docs, and ADRs.
- The theory cannot be reconstructed only from the artifacts in the git repository [Naur].
- The LLM struggles with large programs. They remain too large for it to hold it all in the conversation and avoid context rot.
As such, an agent struggles to understand the program's theory and fulfill the programmer's role. This is why the design is a conversation with the agent. This is why the loop must be observed. As the programmer, you are developing the program's theory.
This, then, is the danger of handing the role of programmer to the agent, rather than using it as a researcher. You no longer have the program's theory, which will cause the software to decay with modification.
This is why, when working with an agent, it is important to observe the loop: we need to build the program's theory. We may choose to work either as a pair programmer, reviewing tests and implementation as they are developed, or as a code reviewer, reviewing the agent's PR. Again, both will be easier if we shift left and put more effort into designing our program and building a clear theory.
Agents' speed at writing code does mean that the old conflict, in which design insights that update our theory are much more easily applied, persists. With hand-written code, we may resist the amount of work a change to the theory represents for an insight. But with an agent, we just ask the agent to update the design, change the tasks, and add tasks to modify existing code.
Of course, updating the design for a new theory requires tests that confirm the behavior remains unchanged when we change the theory. This is why we practice TDD. (This is also why we do TDD against behaviors and not details – because we want to be able to revise our theory, not make it rigid).
A Programming Episode with Brighter
As I am writing this, I am working with an agent to pick up a backlog item for Brighter. Configuration for Brighter can be hard. Even for simple CQRS, you need to ensure that pipelines are consistently sync or async, handlers are registered, and when you use messaging middleware, message mappers and transformers, subscriptions and publications, reactor and proactor pipelines, the whole thing has plenty of opportunities to trip users (including agents) up. The “pit of success” for Brighter is a major source of friction, leading developers to reject us in favor of other frameworks.
What we need is static analysis, diagnostics, and dynamic analysis (Roslyn) to help. It looks like a useful backlog item to burn some tokens on.
Working with an agent to fulfill this, once we outline the requirements, requires us to pass our ADR steps.
We use our workflow spec:design to kick this off, and the agent has made a pretty good attempt to design a tool that meets the requirements.
But Brighter is a mature codebase, so it gets it wrong. It can't hold all of our code in its context. Its approach isn't dumb; it just misses a lot. It fails to understand the levels at which configuration can occur: local, with producers to the external bus, and with configuration to an external bus.
It doesn't yet have a theory for how to do this.
I give feedback on it. I explain the theory of the levels of configuration. I tell it about IBrighterBuilder and how that can help.
It refines its approach. It's better, but while it recognizes that we need a model of our pipelines, it fails to associate that with using our IAmAPipelineBuilder<T> to create pipelines; instead, it describes (a dry run, as I call it) rather than building.
I give it more feedback. I explain the theory behind using IAmAPipelineBuilder<T> to populate a model describing a pipeline for validation and reporting.
We re-run, and now it proposes extending PipelineBuilder with describe methods to build a model. This looks better.
I notice how it is setting up its rules. We have an implementation of the Specification pattern already checked in for future functionality. It is in an assembly that depends on this one, but we can move it and its tests. I discuss it with the agent as a better way to implement this.
This is iterative, a conversation with the agent as we work out the theory of how this fits together. I already hold much of the theory of how Brighter works. I can extend that theory to what might work to implement this feature. The agent can pursue this faster than I can, by reading existing code and figuring out what it would take to make it real.
This is programming. We are building the theory of how this works.
Cognitive Debt
What happens if we don't build on the programmer role, build the theory, but instead delegate the programmer role to the agent? We are already beginning to see that this problem is happening and being recognized.
- Cognitive Debt increases – the gap between our theory about the program and the code and documentation. Naur tells us that documents are not enough here.
- Because of the lack of theory, it becomes hard to make decisions.
- Coherence declines. The software no longer has one theory; the agent lacks context for this. Instead, multiple theories exist. As the number of theories grows, our ability to make decisions rots, because there is no theory to make them against.
- Our software becomes a “big ball of mud,” and the only way to recover the theory is to rewrite it.
- Production issues become hard to fix because no one has the theory anymore.
- Indeed, some companies may find that their “legacy” code problem becomes existential.
We have to own the theory; the speed that coding agents offer in writing code leads us to forget that we need to build the theory, too.
Can LLMs Build Theory?
Agents are continually new developers who struggle to retain the theory, even when it is presented to them in conversation. So agents, like new developers, don't have the theory and can be coders but not programmers without supervision.
When using an agent, developers experienced with the codebase may be slower, precisely because they need to explain the theory to the agent. For short tasks, where explaining the theory might take longer than just doing the work, manual effort may be faster because of this cost.
As codebases expand, we seem to encounter increasing issues in codebases where the programmer role has been delegated to an agent with no theory, which thus treats every new requirement as novel. This accretes multiple theories into the codebase, which eventually becomes incoherent for agents or people.
Will Agents Develop Theory?
Theory is our goal when building software, a theory that is shared with the machine, our colleagues, and everyone else.
Memory is the key problem for agents with theory, both forgetting the theory behind changes and the amount of context required to keep those decisions in mind when modifying existing code. It's possible that developments in LLMs over time will break down this problem, allowing agents to build and retain theory. An agent with persistent memory, access to all historical conversations and decisions, and the ability to track the codebase's evolution over the years could potentially hold a theory.
A sufficiently capable model reading a mature codebase can probably identify the patterns in the code. But theory isn't this pattern recognition — it's the understanding of why those patterns were chosen. That “why” lives largely outside the artifacts. It's in the conversations, the rejected PRs, the ADR that was never written, the whiteboard that was wiped. It's in the philosophy. (For example: It's the why of Brighter choosing to have a single-threaded message pump over using the thread pool).
The deeper issue is that theory is socially constructed and maintained. It exists in a team's shared understanding, updated continuously through conversation, pairing, review, and argument. An agent can participate in a single conversation but can't be a persistent member of that social process — at least not in any current architecture. Memory features help at the margins, but don't change this structurally. Even if the agent could acquire a theory, it would remain problematic for humans to collaborate if they cannot socialize that theory with the agent.
The question is whether an agent can be a persistent, socially-embedded participant in theory construction — and nothing about current trajectories suggests that's imminent, because it requires continuity of identity and stake in outcomes that agents don't have.
For now, then, the programmer role requires a person.
A Programming Episode with Brighter
Reviewing the ADR, the agent wrote, I realize we now have two approaches to validation. One uses our Specification<T> pattern, but the other creates a bespoke validation infrastructure. This seems ugly. If we are moving to the Specification<T> pattern, why do we still have a bespoke class to check our pipeline?
After reviewing the ADR, I realize the issue is reporting failures. Our Specification<T> pattern will give you pass/fail, but won't tell you which rule failed and why. It also explains an earlier issue in which the review noted that we were throwing an error from a Specification<T> when we reached a failure case that should not occur. We need to implement the Visitor pattern in our specification to collate all the errors.
I explain this change to the agent, noting that using the Visitor pattern will allow us to accumulate error messages in the graph, which can be retrieved if the combined specification evaluates to false. I tell the agent to ask me questions so that we can have a dialogue about this design.
The agent tries to overcomplicate this at first. When it answers, it can't figure out how to make this work. At a guess, the model doesn't recognize this approach. It can't initially see how to translate the multiple rule failures from its bespoke code, so it comes up with a ForEachSpecification<T>. I have to walk the agent back to basics on this approach, explaining that each Specification<T> is a rule; a rule may result in multiple breaches, to be recorded in an IEnumerable<ValidationResult>. I then explain that if there are any results, the predicate fails. The visitor pattern is then used to retrieve the results. I suspect that I assumed the agent understood this pattern combination, but it does not.
The agent now understands and presents a summary. The summary matches my expectations, so I ask it to go ahead and change the ADR.
The code looks simpler. I spot some failures to extract methods, leaving a complex implementation. Although this is just an ADR, I will have the agent change it now.
Overall, this conversational process is faster than writing this out by hand. We are getting closer iteratively.
But I also appreciate that I had simply accepted this, without properly reviewing, I would have had something less maintainable, because there were no clear patterns flowing through the code, but different ideas lashed together. I have worked on codebases where new insights did not lead to refactoring, leaving the codebase feeling like a lesson in decision archaeology. That was what would have happened here, without effective review. Because I took on the agent's roles as a researcher and a programmer, we iterate toward a cleaner design.
I feel comfortable spending more time here than I did before. The rush to get to writing code is gone. The agent can handle that quickly. Instead, I iterate on the design, confident that the agent can deliver it quickly.
New Developers, LLMs, and Theory
Why are senior developers more productive with coding agents?
- They already have the theory, and they can explain it to the agent.
- Once you have the theory, it is easy to produce new coding specifications.
- Once you have a coding specification, the agent can write the code far faster than humans could.
A senior developer can fulfil the role of a programmer.
By contrast, a new developer (experienced or not) lacks the necessary theory and will make mistakes when specifying a program for an agent. Someone with the theory must thus review the new developer's code (when using an agent), since the new developer does not yet have it.
A new developer has to learn the role of a programmer on this team, as they don't have a grasp of the program's theory. How do you onboard someone onto a team? Through ADRs, documentation, code reviews, conversation, and social inclusion. An acceptance that they will be slower.
- A junior developer is still working on the skills required to build theory; they will be slower.
- A new developer on the team will need to acquire the theory; they will be slower.
So, before we can be productive with agents, we have to learn the program's theory. We accept that they will go slow when they don't have the theory. And that remains the answer. The junior developer needs supervision from the senior developer. The new developer needs onboarding. Only once they grasp the theory can they write new specifications without supervision.
Even the senior developer will need to slow down at times. Novel changes will require even senior developers to build a theory; they will be slower. You can be fast when you have the theory, and the change is “boilerplate” for you. You must be slower in novel situations that require theory building. Indeed, where the code is novel, pair with the agent to review each test and each implementation. Your goal here is less “correctness” of syntax, the provenance of the coder, but acquiring the theory, the provenance of the programmer.
The question you need to repeatedly ask now is: Do I have the theory here? Only then, go fast. How do you know if you have the theory? Can you explain it to someone else?
For a junior, that means the same way as before — pairing, reviews, elaboration.
Does Stack Matter?
One simplistic idea is that the stack you use does not matter. Now that you can use an agent to write the code, what does it matter what stack you write it in? The problem comes down to whether you can build the theory of the program if you don't understand the stack. In some situations, you may be able to understand the theory without knowing the language, but in others, the nuances of how we use language features to represent program theory may be important. Typically, as complexity grows, so does the likelihood that the stack – not just the language but the frameworks and libraries we use – is important to the theory, and as such, we have to understand it.
In cases where we need to understand the stack to build the theory, this would create unmaintainable code in which the programmer does not understand the stack they are working with.
The Need for Speed
“There's a lot of noise around how “Ai generates buggy software”. The truth is writing the code was always 20% of the time. Testing and refining was always 80%. But now as that 20% compresses 10x, we want to compress the 80% as well... That's the mistake.” Balint Orosz, X.
The pressure with AI is to take the productivity benefits of eliminating the coder role and apply them to removing the other roles: analyst, designer, and programmer. It's tempting, surely you just need to configure an agent to perform that role, and you will go even faster.
The problem is that whilst agents can take on the coder role, particularly when we iterate towards a solution, their tirelessness enables us to iterate towards quality code. But the programmer role, building the theory of the software, using discernment and judgement, remains the purview of the “human in the loop,” not an agent.
“All code must be human reviewed, and you should not send a PR for review unless you can personally vouch for it. That means pre-reviewing the code your agents generate before it gets reviewed by a colleague in an actual PR review... but coding was only ever half the job to begin with. Now we have more time for the other half (which largely consists of figuring out *what* to even build)” Nick, @Theurgistic, X.
We have the opportunity to improve the quality of the code produced by using agents and to achieve genuine productivity gains, but we can remove only one role here.
“When it comes to AI agents / AI tooling + coding, I hear an awful lot of talk about:
Efficiency
Iteration speed / PR output rate / lines of codes produced
I hear zero mentions about:
Quality
Customer obsession
This will bite back, and it probably already is...” Gergely Orosz, X
Return of the Programmer
Armed with the understanding that we have merged two roles in our thinking for years, how does this help us think about the future for software engineers?
In the era of agents writing code, this distinction between *programming* and *coding* becomes important. With coding agents, the agent is fulfilling the role of the *coder* at the levels of accuracy that mean it is rapidly taking over that task. But human software engineers continue to own the task of *programming*. The two have been merged in recent years, but we need to recognize their differences to make better decisions about who owns each task. The important role for the *programmer* is building the theory of the program. Without theory, we risk cognitive debt and unmaintainable software.
Copyright © Ian Cooper 2024+ All Rights Reserved.